

Taming the Stochastic Beast: Past Prompting. I’m on this summer time get together mingling with sensible enterprise & tech individuals. Everyone seems to be merrily sipping potent cocktails whereas proclaiming their seemingly huge experience in ChatGPT prompting. I strategy a gaggle of three blokes, and only for enjoyable I ask: ”How would you management the outputs from a stochastic parrot?” I get clean faces. Then one among them asks me: “One other Daiquiri maybe?”
Some time in the past researchers at Berkeley & Cornell Unis revealed this paper: Why Johnny Can’t Prompt: How Non-AI Experts Try (and Fail) to Design LLM Prompts Most undoubtedly, I’m going to ship the paper to the those that attended the summer time get together.

LLMs in enterprise. One factor is to do fancy innovation experiments in your organization with ChatGPT. Fairly one other factor, is to persistently get correct, dependable, reliable outputs for what you are promoting from an LLM in manufacturing, at scale, cost-efficiently.
Past prompting: steering. Utilizing some intelligent or advanced prompting like: in-context learning, CoT, ToT, ReAct, self-consistency… received’t be sufficient to all the time getting correct, dependable outputs persistently. And fine-tuning, reward modelling, and (for the wealthy) RLHF, should not ship what what you are promoting wants. Because of this, many buyers, researchers and corporations are setting there sights in “LLM steering” or a collection of recent strategies and instruments to enhance LLM consistency, reliability in a time and value environment friendly, scalable approach.
Detecting problematic prompts. A key facet of your LLMOps ought to be monitoring your mannequin’s immediate/response embeddings efficiency. Here’s a new tool to monitor LLM’s outputs and detect problematic prompts.

Begin by grounding the LLM. Grounding is the method of utilizing LLMs with info that’s use-case particular, related, and never out there as a part of the LLM’s educated data. Researchers at MSR counsel that it is best to first discover the probabilities of Retrieval Augmented Generation earlier than resorting to fine-tuning.

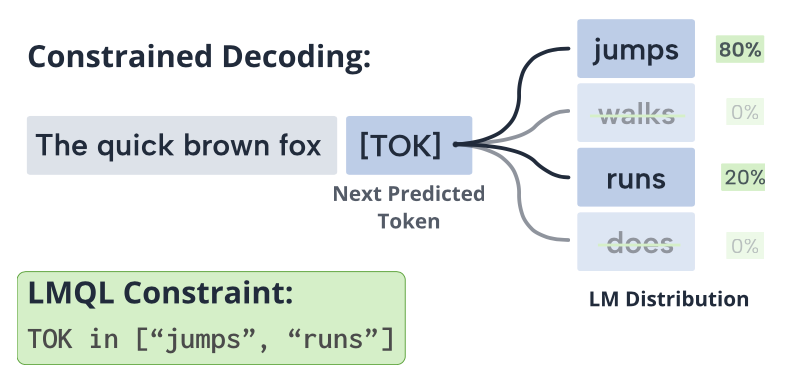
Use a DSL for constraining LLM outputs. One other strategy is to make use of a DSL to specify high-level, logical constraints over the LM output. This enables to implement many constraints strictly, making it not possible for the mannequin to generate content material that doesn’t fulfill the necessities. Checkout: LMQL: A programming language for LLMs
Put some guard-rails across the LLM. Test this new Python package called Guardrails. It enables you to add construction, kind and high quality ensures to the outputs of LLMs, and in addition takes corrective actions (e.g. reasking LLM) when validation fails.
Apply DPO: A brand new coverage algorithm. imo it is a essential improvement.…In late Could, Stanford researchers launched Direct Desire Optimization (DPO): a brand new steady, performant and computationally environment friendly coverage, that eliminates the necessity for becoming a reward mannequin, sampling from the LM throughout fine-tuning, or performing vital hyperparameter tuning. Paper: Direct Preference Optimization: Your Language Model is Secretly a Reward Model

Steer the LLM with Monte Carlo. Researchers at MIT, simply launched a brand new inference-time strategy to imposing syntactic and semantic constraints on the outputs of LLMs, known as sequential Monte Carlo (SMC) steering. Utilizing SMC you may steer LLMs to resolve various activity with create management of the outputs. Paper, repo: Sequential Monte Carlo Steering of LLM using Probabilistic Programs

Have a pleasant week.
MAGVIT: An Amazing, New Video Transformer (demo, paper, code)
[free book] Information Theory: From Coding to Learning (pdf, 599 pages)
Ideas? Options? Suggestions? email Carlos
Curated by @ds_ldn in the course of the evening.









{kind=link}